Исходная MR-задача Grep
Наш первый эксперимент основывался на задаче Grep из исходной статьи про MR, в которой она описывается, как "представитель большой части реальных программ, написанных пользователями MapReduce" . При решении этой задачи каждая система должна просканировать набор данных из 100-байтовых записей, производя поиск трехсимвольного шаблона. Каждая запись состоит из уникального ключа, занимающего первые 10 байт, и случайного 90-байтового значения. Шаблон поиска ищется только в последних 90 байт каждой из 10000 записей. Мы использовали набор данных объемом в один терабайт, разделенный по 100 узлам (10 гигабайт на узел). Набор данных состоит из 10 миллиардов записей, каждая из которых занимает 100 байт. Поскольку в этой задаче, по существу, требуется выполнить последовательное сканирование набора данных в поисках заданного шаблона, она позволяет простым образом измерить, насколько быстро система может просканировать крупный набор записей. При решении этой задачи невозможно с пользой применить какие-либо сортировку или индексацию, и ее легко запрограммировать как в среде MR, так и на SQL. Поэтому можно было бы ожидать более быстрого выполнения от низкоуровневой системы (такой как Hadoop), выполяняемой прямо поверх файловой системы (HDFS), чем от более тяжеловесных СУБД.
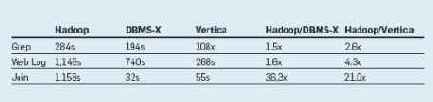
Однако время выполнения, приводимое в табл. 1, показывает удивительный результат: системы баз данных оказываются почти в два раза быстрее Hadoop. Некоторые причины этого явления мы поясняем в разделе об архитектурных различиях.
Табл. 1. Результаты сравнения систем на тестовом наборе